Introducing Multiverse: The First AI Multiplayer World Model
Introduction
We're a team of ex-8200 and alumni from Israel's leading startups, with deep experience across research and engineering - spanning vulnerability research, algorithms, chip-level research, and systems engineering.
With a first-principles thinking mindset, we tackled an open challenge (1 and 2) in AI-generated worlds: Multiplayer world models.
Now available on GitHub and Hugging Face — easily run it on your PC with a single click. Code here and model + dataset here.
What follows is the full technical breakdown - research, engineering, and how we brought it to life.
Multiverse: Architecture Deep Dive
Recap on Single Player Architectures
To understand the architecture of our multiplayer world model, let's first take a look at the existing architectures used in single-player world models:
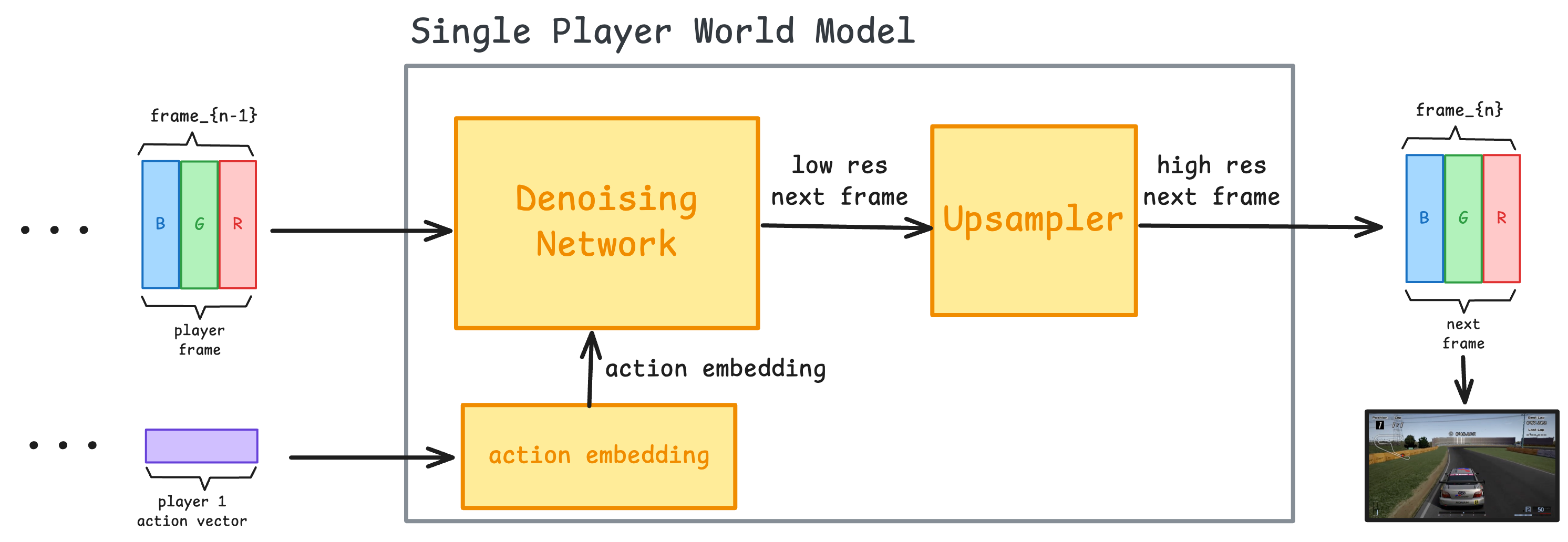
The model receives a sequence of video frames along with the user's actions (like key presses), and uses this information to predict the next frame based on the current action.
It does this through three main components:
- The action embedder - converts the actions into an embedding vector
- The denoising network - a diffusion model that generates a frame based on the previous frames and the action embedding
- The upsampler (optional) - another diffusion model that takes the low resolution frame generated by the world model, and increases the details and resolution of the output.
Our Multiplayer Architecture
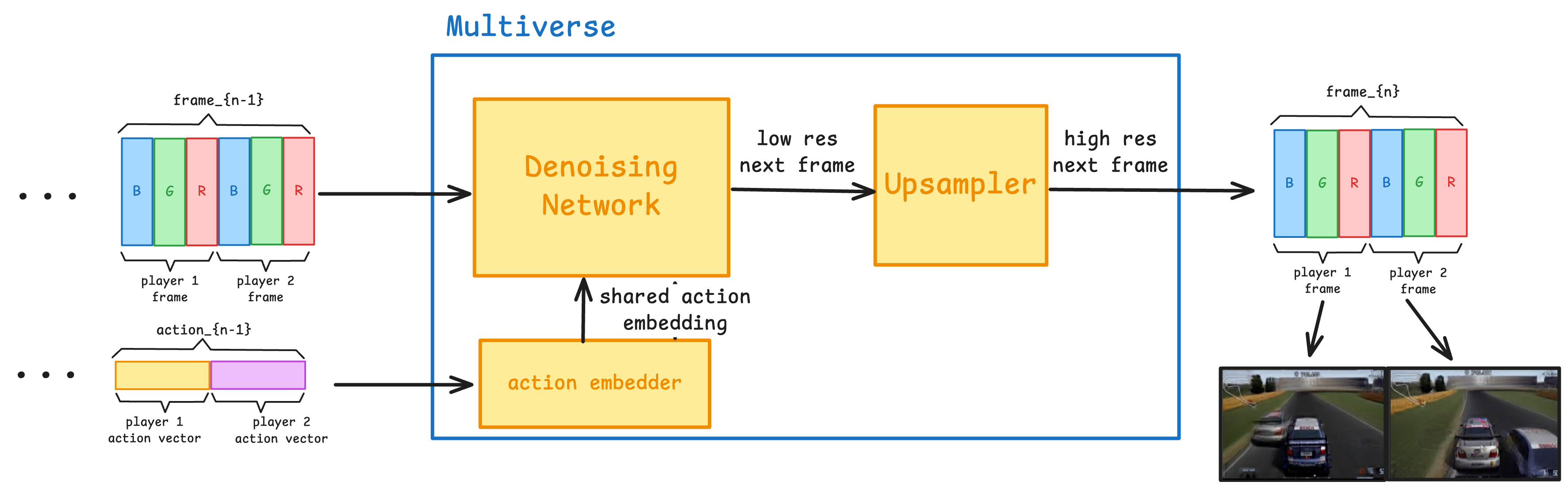
To build a multiplayer world model, we kept the core building blocks but tore apart the structure, rewired the inputs and outputs, and reworked the training process from the ground up to enable true cooperative play:
- The action embedder - Takes both player's actions, and outputs a single embedding that represents both of them
- The denoising network - a diffusion network that generates both player's frames simultaneously as a single entity, based on the previous frames and action embedding of the two players.
- The upsampler - This component is very similar to its single player counterpart. Although our upsampler takes in the two frames, one for each player, and computes the upsampled version simultaneously.
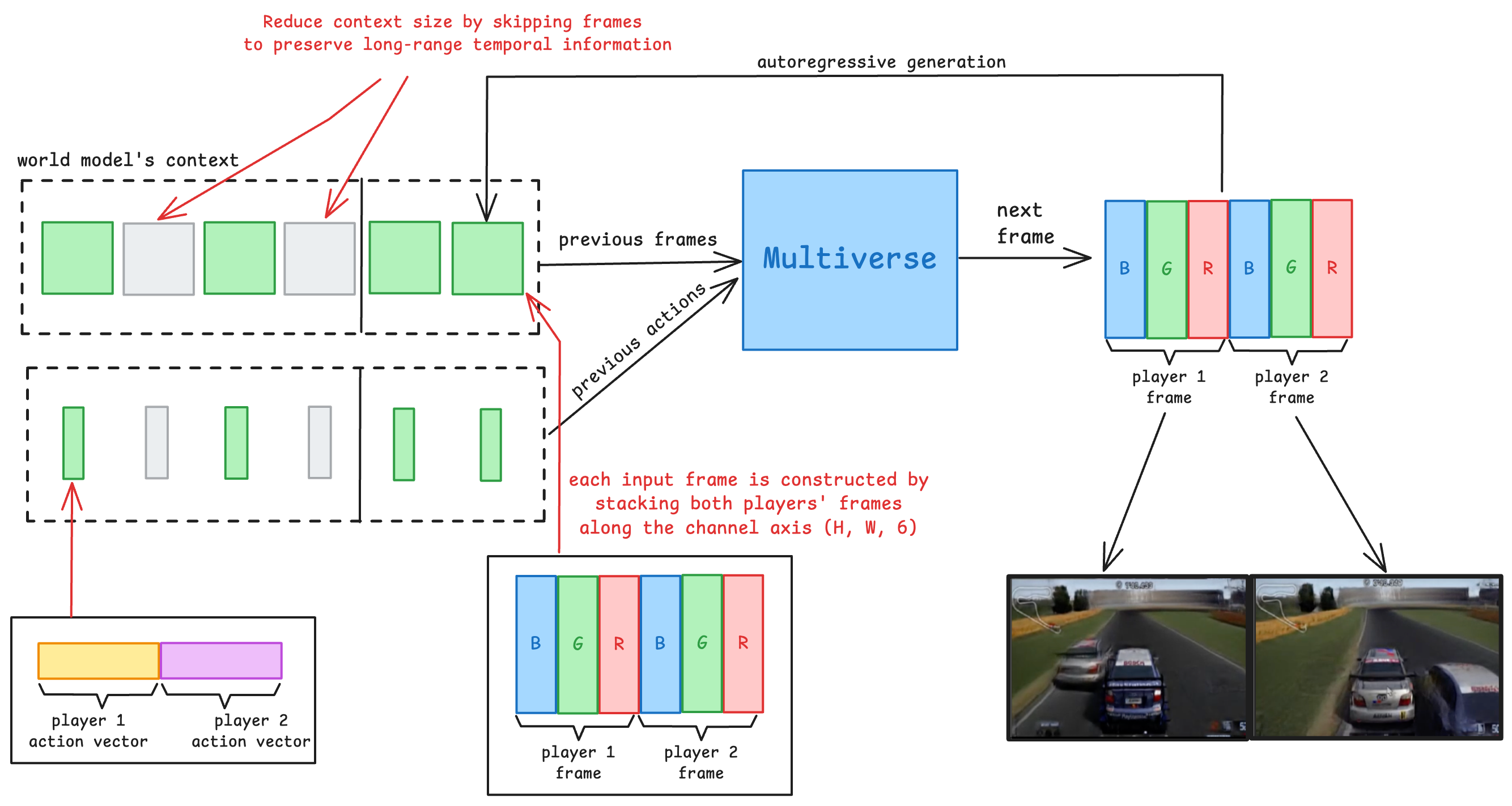
To create a multiplayer experience, our model needs to take in the previous frames and actions of both players, and output predicted frames for each of them. The catch? These two outputs can't just look good on their own—they need to be internally consistent with each other.
This is a real challenge because multiplayer gameplay relies on a shared world state. For example if one car drifts in front of the other or causes a collision, both players should see the exact same event from their own perspective.
We propose a workaround: stitch both player views into a single image, mash their inputs into one joint action vector, and treat the whole thing like one unified scene.
This raised a key question: what's the best way to merge the two player views into a single input the model can process?
- The obvious move is to stack them vertically—just like classic split-screen games.
- A more interesting option is to stack them along the channel axis, treating both frames as one image with twice the color channels.
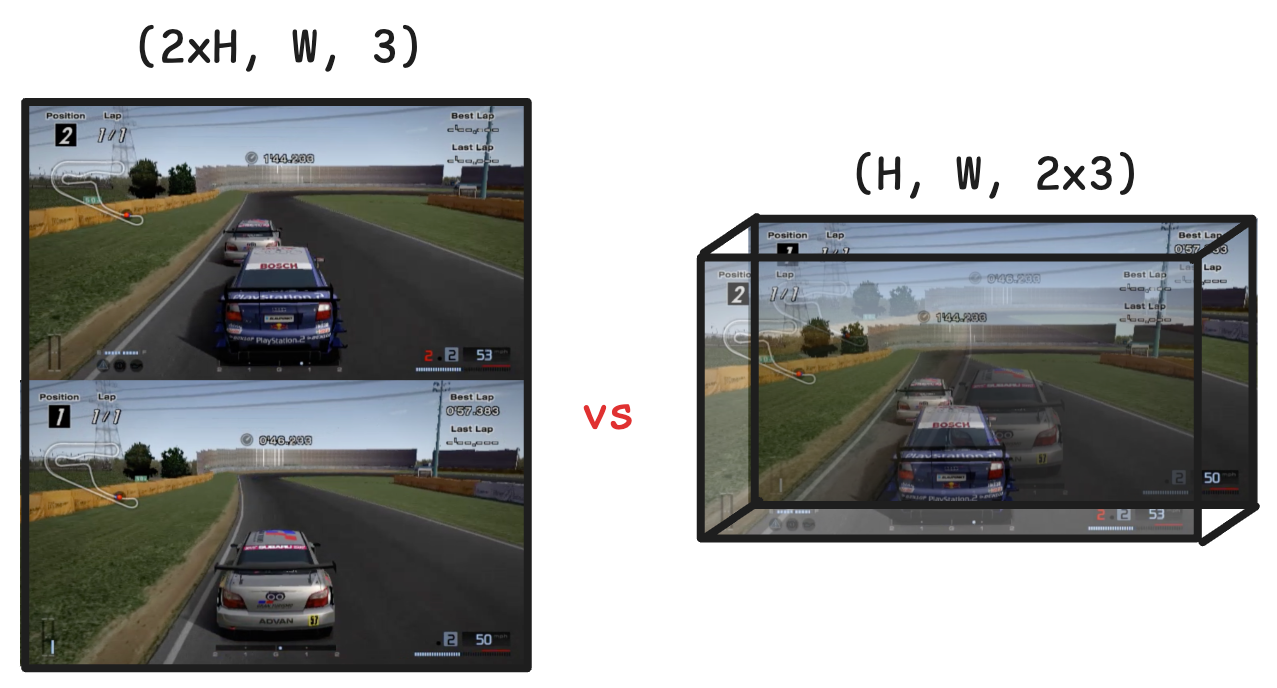
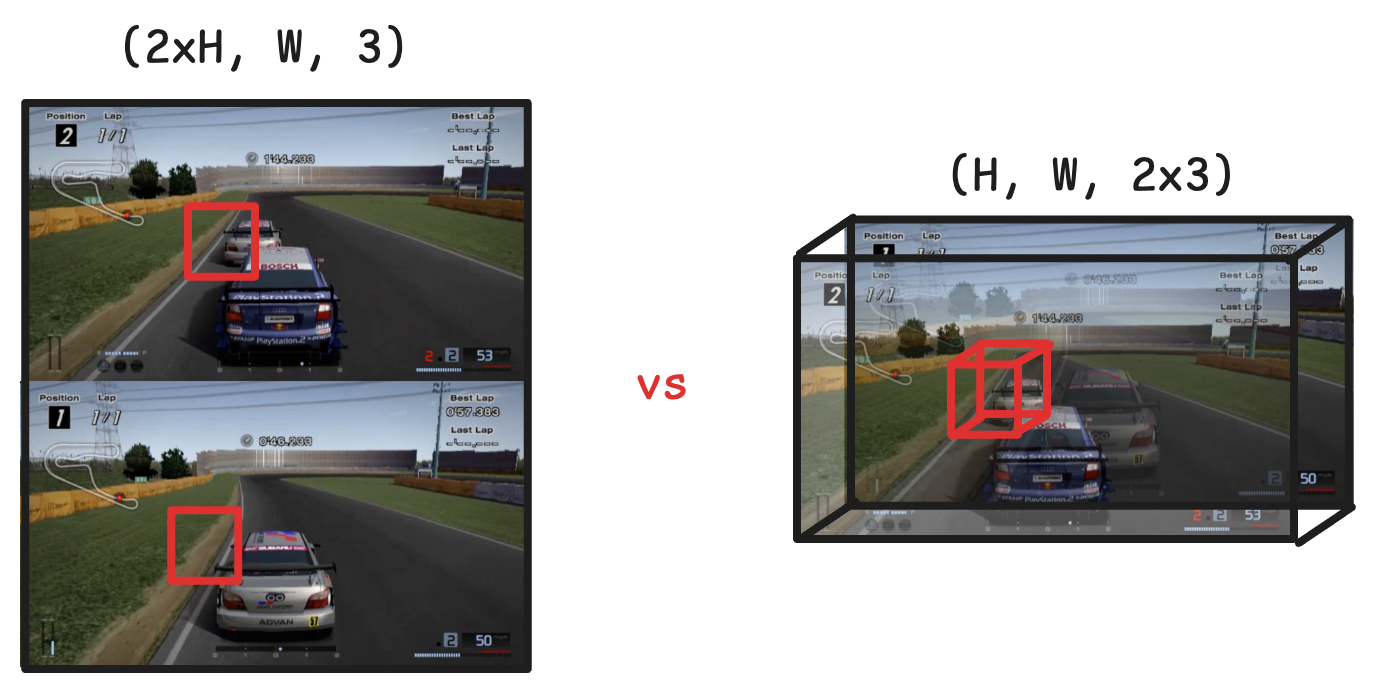
The answer turned out to be option 2, stacking them along the channel axis. Because our diffusion model is a U-Net, made mostly of convolution and deconvolution layers, the first layers only process nearby pixels. If we stack the two frames vertically, the frames aren't being processed together until the middle layers. This reduces the model's ability to produce a consistent structure between the frames.
On the other hand, when stacking the frames on the channel axis, the two players' views are being processed together on every layer of the network!
Efficient Context Extension for Modeling Vehicle Kinematics and Relative Motion
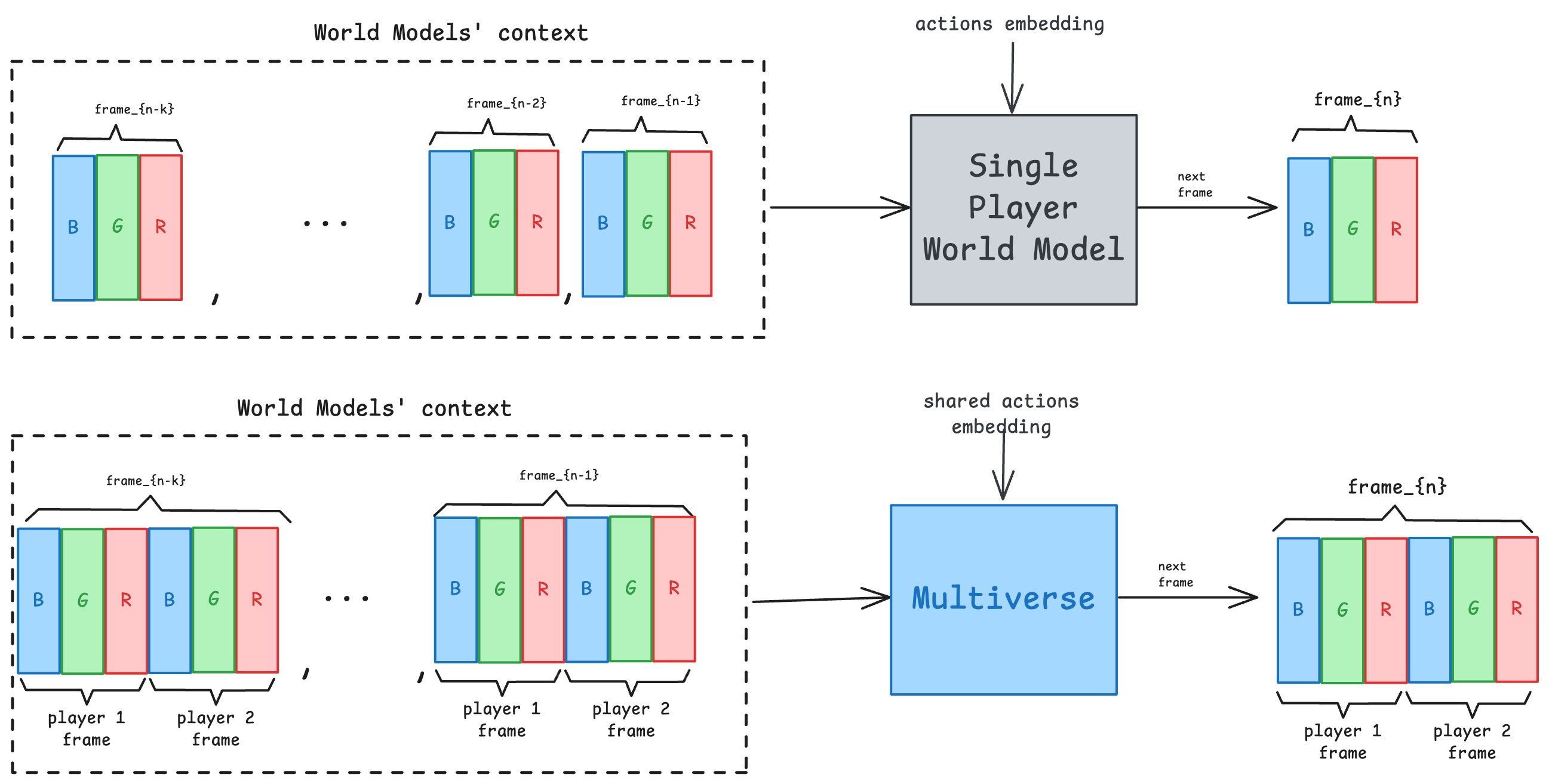
To accurately predict the next frame, the model needs to receive the player's actions like steering inputs, and enough frames to compute the velocities of both vehicles, in reference to the road and each other.
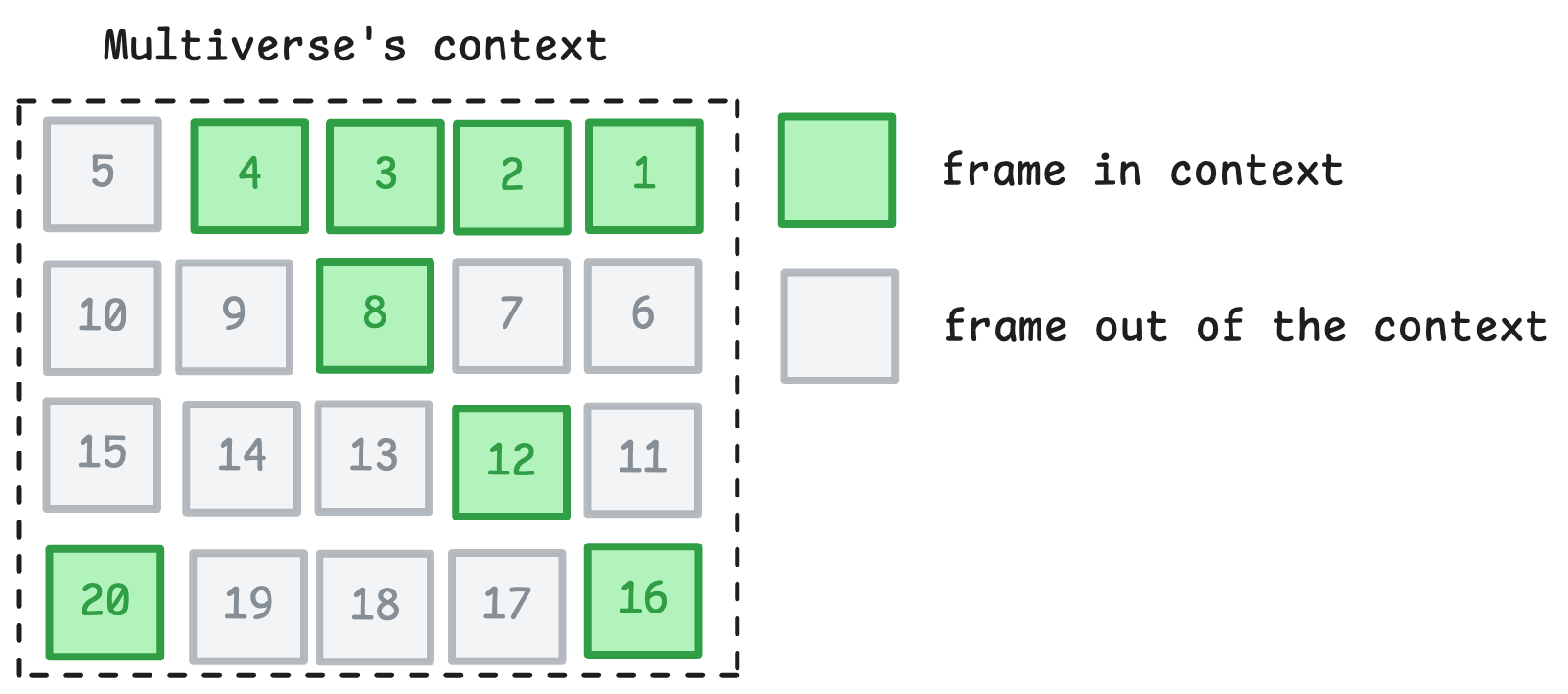
In our research we've found 8 frames (at 30 fps) allow the model to learn vehicle kinematics, like acceleration, braking and steering. But the relative motion of both vehicles is much slower than to the road. For example the vehicles travel at ~100 km/h, while an overtake has a relative velocity of ~5 km/h.
To capture this relative motion we needed to almost triple the context size. But that would make the model too slow for real time play, increase its memory usage and make training much slower. To maintain the context size but allow larger temporal information, we provide the model with a sparse sampling of the previous frames and actions. Specifically, we provide it the latest 4 frames. Then we provide every 4th frame for the next 4 frames. The earliest frame in the context is 20 frames old, 0.666 seconds in the past, enough to capture the relative motion of the vehicles. As an added bonus, this allows the model to capture the velocity and acceleration compared to the road better, which makes the driving dynamics even better.
Training for multiplayer
In order to learn driving and multiplayer interactions, the model needs to train on such interactions. Walking, Driving and other common tasks in world models require small prediction horizon, for example 0.25 seconds into the future.
Multiplayer interactions take an order of magnitude longer. In 0.25 seconds the relative motion between the players in almost negligible. To train a multiplayer world model, we needed a much longer prediction horizon. As such, we trained the model to predict perform autoregressive predictions (at 30 fps) up to 15 seconds into the future.
In order to allow the model to perform such long horizon predictions, we've employed curriculum learning and increased the prediction horizon during training from 0.25 seconds up to 15 seconds. This allows efficient training during the initial training phase, when the model is learning low level features like the car and track geometry. And trains it on high level concepts like player's behaviour once it has learned to generate coherent frames and modelling vehicle kinematics.
After increasing the prediction horizon, the model's object permanence and consistency between frames have increased significantly.
Efficient long horizon training
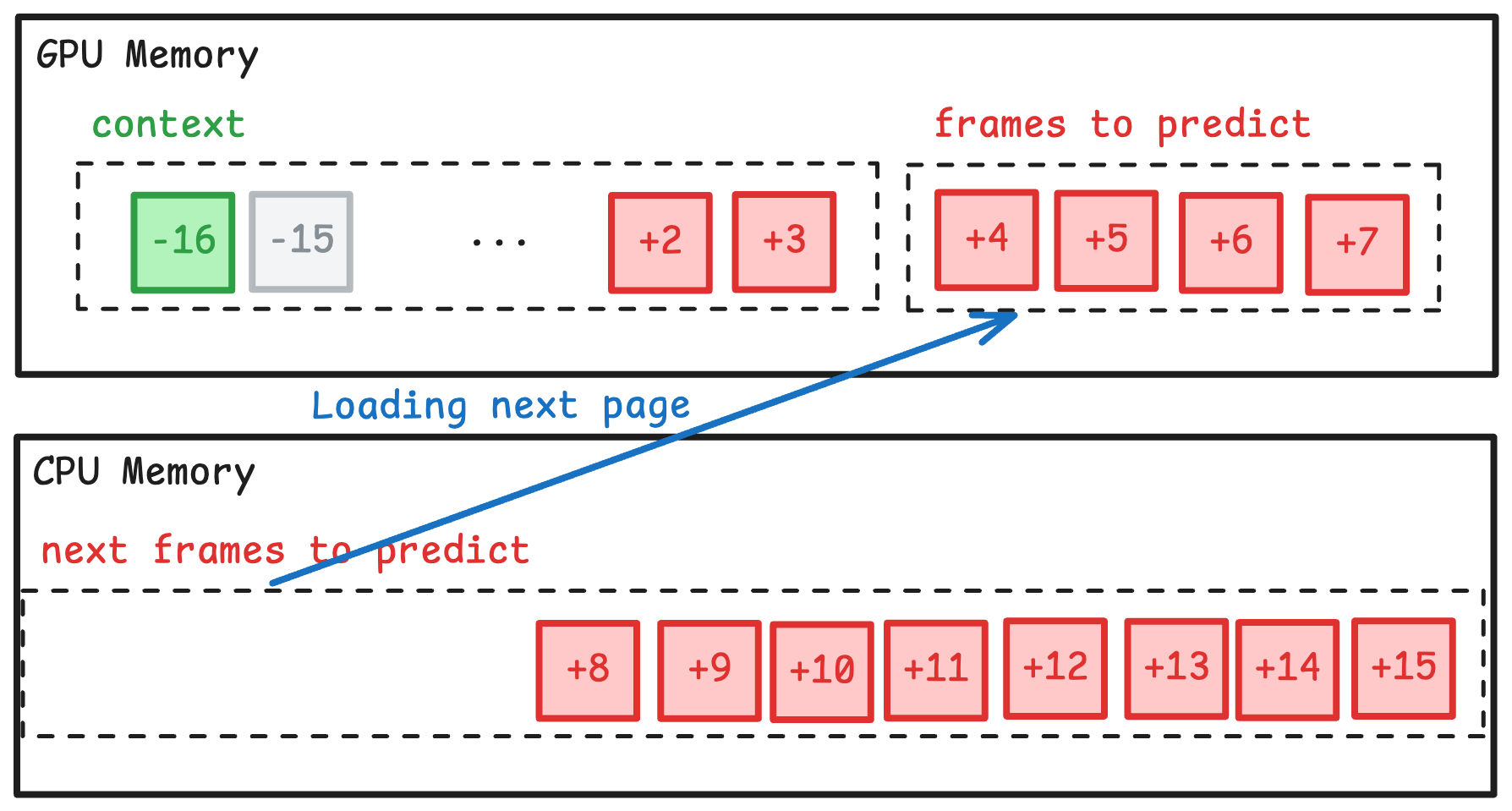
Training a model for more than 100 frames in the future poses a VRAM challenge. As loading the frames into the GPU memory for autoregressive prediction becomes infeasible in large batch sizes.
To address this memory constrained, we perform autoregressive predictions in pages.
In the beginning of training, we load the first batch and perform a prediction on it.
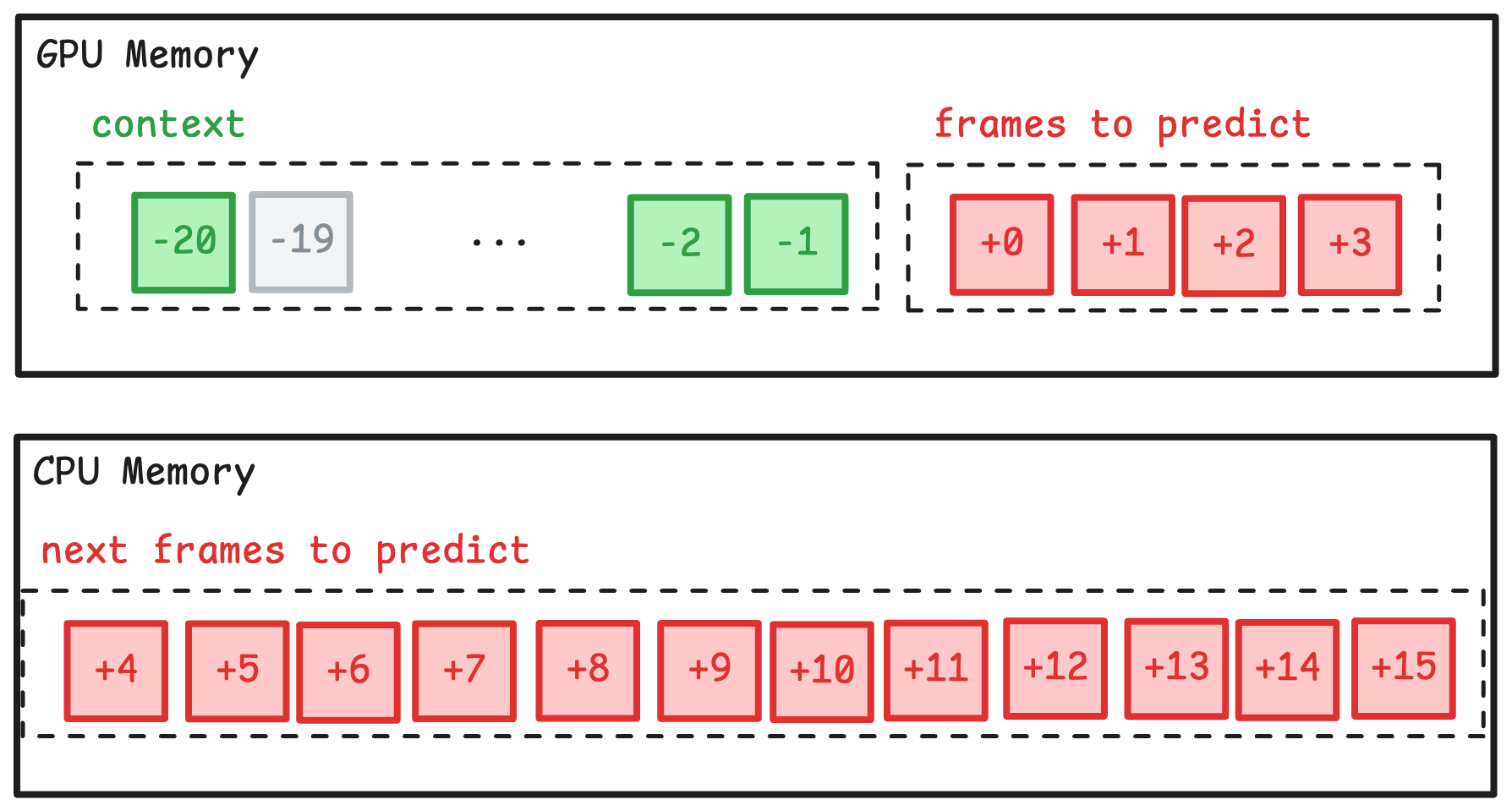
Then load the next page and discard the frames that would be outside the context window.
Gran Turismo Dataset: Generation and Collection Deep Dive
We trained our model on Gran Turismo 4 — Sony, this is just a demo and we're die‑hard fans, so please don't sue us.
Setup and Game Modification
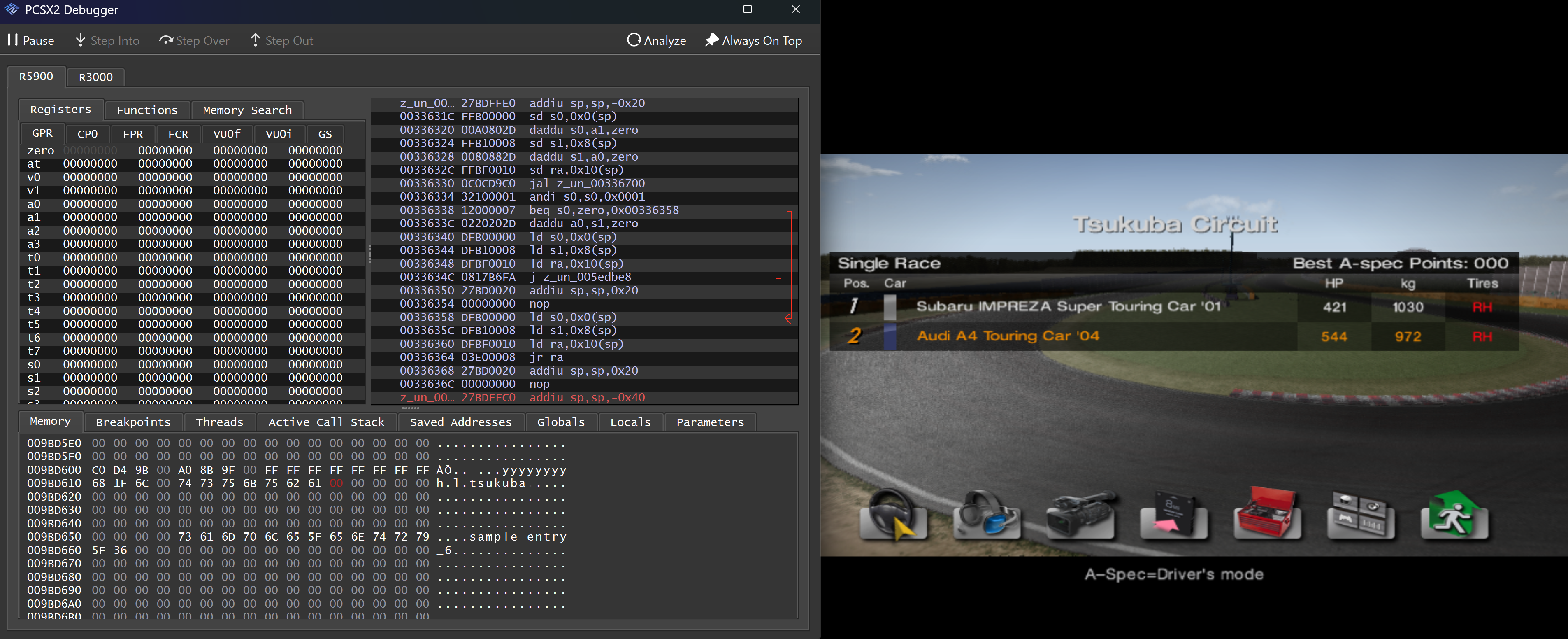
Our test case is simple: a 1‑v‑1 race on Tsukuba Circuit in third‑person view. Tsukuba is a short, uncomplicated track which was ideal for training.
The catch: Gran Turismo 4 never lets you run Tsukuba as a full‑screen 1‑v‑1. The game only offers it as 1‑v‑5 or split‑screen head‑to‑head. To get the setup we wanted, we reverse engineered and modified the game to launch Tsukuba in a true 1‑v‑1 mode:
Data Collection
To collect third-person video data from both players, we leveraged the in-game replay system—replaying each race twice and recording from each player's perspective. Then we synced the two recordings to match the original two-player race, combining them into a single video of both players playing together at the same time.
Now, you might be wondering: how did we capture the keypresses for our dataset, especially since one of the players was a game bot, not a human?
Luckily, the game displays enough on-screen HUD elements—like throttle, brake, and steering indicators—to accurately reconstruct the control inputs needed to reach each state:
Using computer vision, we extracted these bars frame by frame and decoded the control inputs behind them. This let us reconstruct the full set of keypresses directly from video, making it possible to build our entire dataset without any direct input logging. Pretty neat.
Data Generation - Autonomously
At first glance, it might seem like we had to sit and manually play the game for hours, recording two replays for every match—painful, right?
While part of our open-source dataset does come from manual gameplay, we discovered a much more scalable method: B-Spec Mode. This Gran Turismo mode revolves around the player using the gamepad or steering wheel to instruct a game bot driver to race on their behalf.
Since B-Spec controls are limited and simple, we wrote a script that sends random inputs to B-Spec, triggering races autonomously. The same script then recorded the replay footage from both perspectives to capture third-person video of these AI-driven matches.
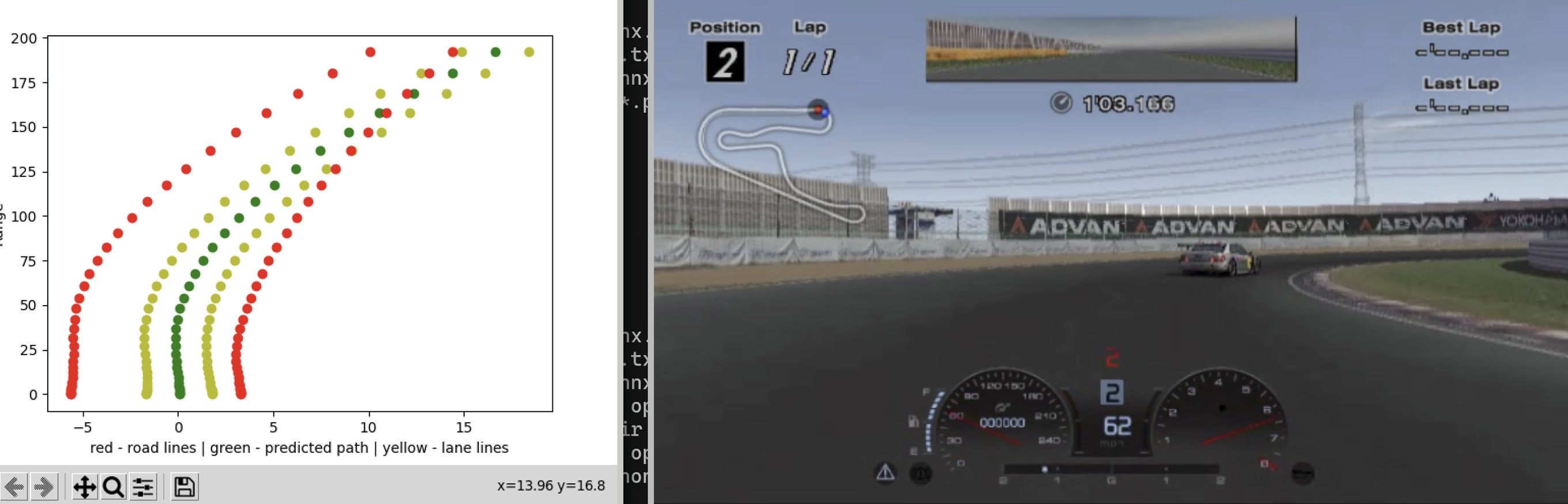
We also experimented with using OpenPilot's Supercombo model to control the cars, essentially turning it into a self-driving agent within the game. While that approach worked, it ended up being unnecessary—so we stuck with B-Spec for data generation in the final version:
Summary
Multiplayer world models aren't just a gaming breakthrough, they're the next step in AI's understanding of shared environments. By enabling agents to learn, react, and co-adapt within the same world, these models unlock new possibilities. We're proud to introduce our solution to this challenge and share how we made it real.